Der iPhone-Moment der KI? Nein, es ist der Wikipedia-Moment
Das ist für mich eher der Wikipedia-Moment: Weltweites Wissen wird lokal und transparent zugänglich, und das geschieht nun auch bei den Interpretationen der Künstlichen Intelligenz (KI). Doch passiert das nicht allein durch vermeintliche Zauberei bei den geschlossenen, uneinsehbaren Modellen wie ChatGPT, Claude oder Google Gemini. Sondern künftig mehr und mehr bei downloadbaren Open-Source-Modellen wie LlaMA vom Facebook-Konzern Meta, Falcon von TII aus den Vereinigten Arabischen Emiraten oder Yi von 01.AI aus China.
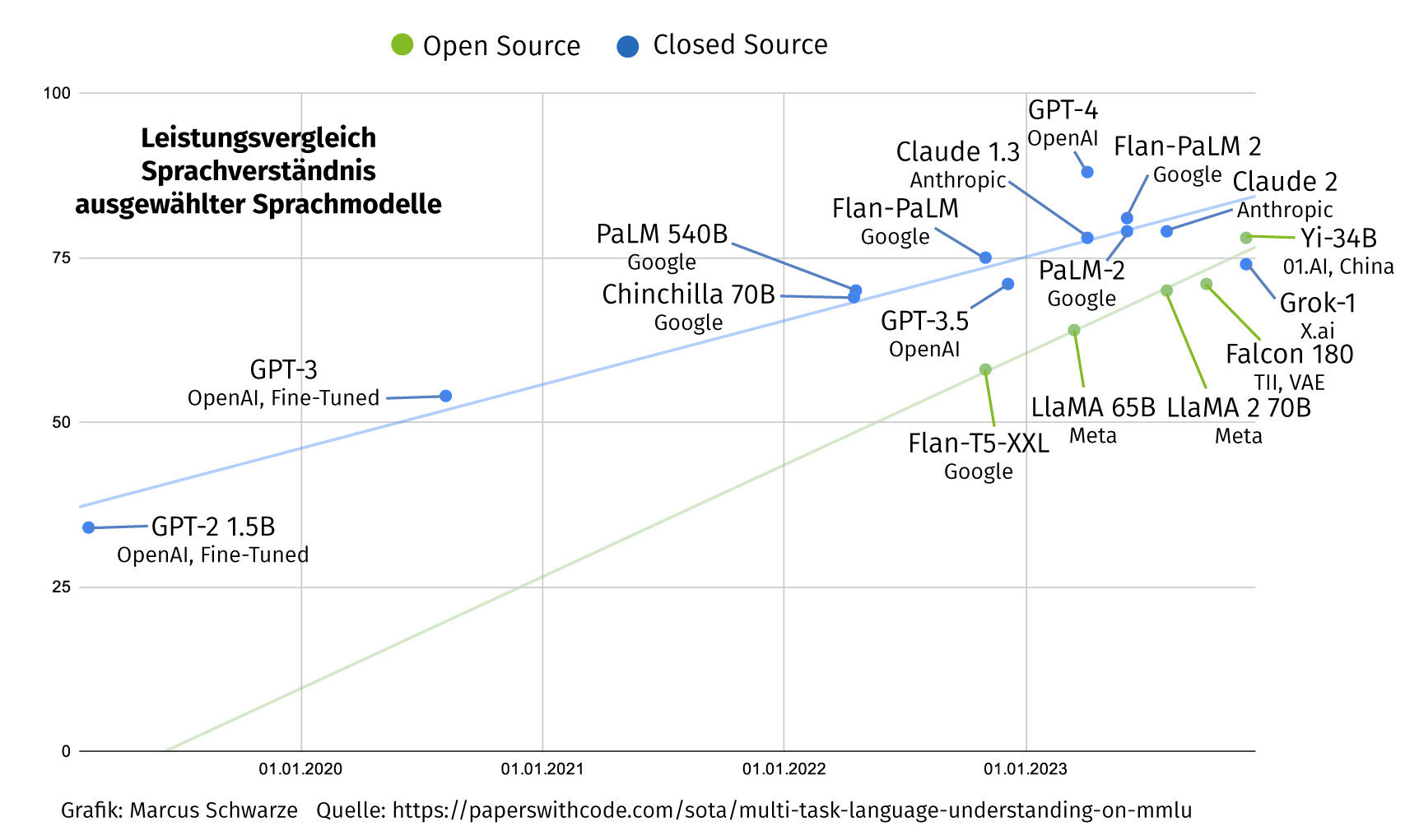
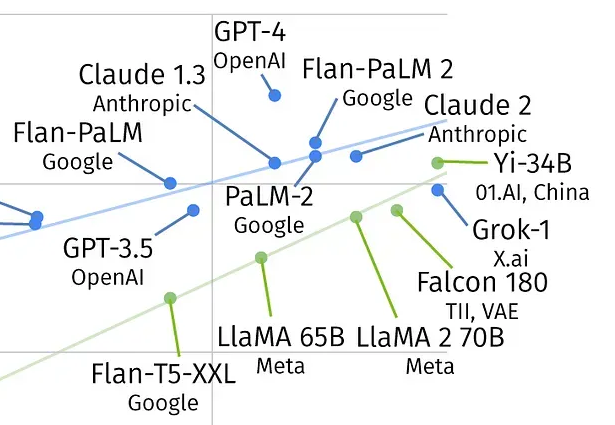
Hintergrund ist ein Leistungsvergleich mehrerer Sprachmodelle. Demnach holen die frei zugänglichen bei der Korrektheit ihrer Antworten gegenüber den geschlossenen Modellen auf. Die grüne Trendlinie in der Grafik dürfte bald auf die blaue Trendlinie treffen. Grün sind die Open-Source-Modelle, blau die Closed-Source-Versionen. Die Leistungsfähigkeit wird hier bei der sogenannten MMLU-Performance gemessen. MMLU steht für „Massive Multitasking Language Understanding“ und beinhaltet einen Test für 57 Themen. Demnach gilt GPT-4 weiterhin als das „beste“ Sprachmodell unter jenen, die keine extra Trainingsdaten enthalten. Das neuere Modell Gemini Ultra von Google rangiert bei diesem Vergleich zwar oberhalb von GPT-4, doch enthält es extra Trainingsdaten, die speziell auf die Testfragen abgestimmt sein könnten.
In der Praxis kann man sich heute bereits eine eigene KI zusammenstöpseln. Basissoftware ist zum Beispiel GPT4All, das für Windows, macOS und Linux erhältlich ist. Aus der Software heraus lassen sich bereits diverse Sprachmodelle herunterladen, die Namen tragen wie Mistral OpenOrca oder GPT4All Falcon. Auch Metas Llama 2 lässt sich dazu installieren, vorausgesetzt, man akzeptiert deren etwas eigenwillige Open-Source-Lizenz. Die erlaubt auch die kommerzielle Nutzung des Sprachmodells, außer man kommt auf mehr als 700 Millionen monatlich aktive Nutzer. Zudem ist für den Download und den Einbau bei GPT4All neuerdings ein Sprachmodell im sogenannten .gguf-Format notwendig, ältere .bin-Dateien funktionieren nicht mehr.
Das zunächst nerdig erscheinende Thema hat auf der Plattform Hugging Face einen weltweiten Marktplatz gefunden. Hier sammelt die KI-Community Open-Source-Bibliotheken und Sprachmodelle. Mehr als 50.000 Organisationen nutzen die Ressourcen von Hugging Face. So können etwa maschinelle Lernprojekte direkt ausprobiert werden. GPT4All ist dabei nur einer von vielen Protagonisten der Szene. Auch Microsoft hat hier Modelle veröffentlicht, etwa Phi-2 als besonders kleines, aber besonders hochwertiges Modell.
Interessant wird GPT4All als vergleichsweise einfache Anwendung, die auf dem eigenen Rechner genutzt werden kann, aus zweierlei Gründen: Zum einen können private Daten fürs sogenannte Finetuning hinterlegt werden. So habe ich etwa meine eigenen Artikel von GPT4All indexieren lassen. Und kann der persönlichen KI Fragen stellen zu Themen, die ich bereits vor Jahren oder Jahrzehnten beschrieben habe.
Zum zweiten können die gewonnenen Daten in einem sogenannten Open Source Datalake beim Unternehmen Nomic aus New York eingespeist werden. Nomic hat die Anwendung GPT4All bereitgestellt. Hier gilt es freilich, genau zu wissen, was man tut. Die Daten werden unter atlas.nomic.ai öffentlich. Deswegen sind personenbezogene Daten auszuschließen und Geschäftsunterlagen gesondert zu schützen.
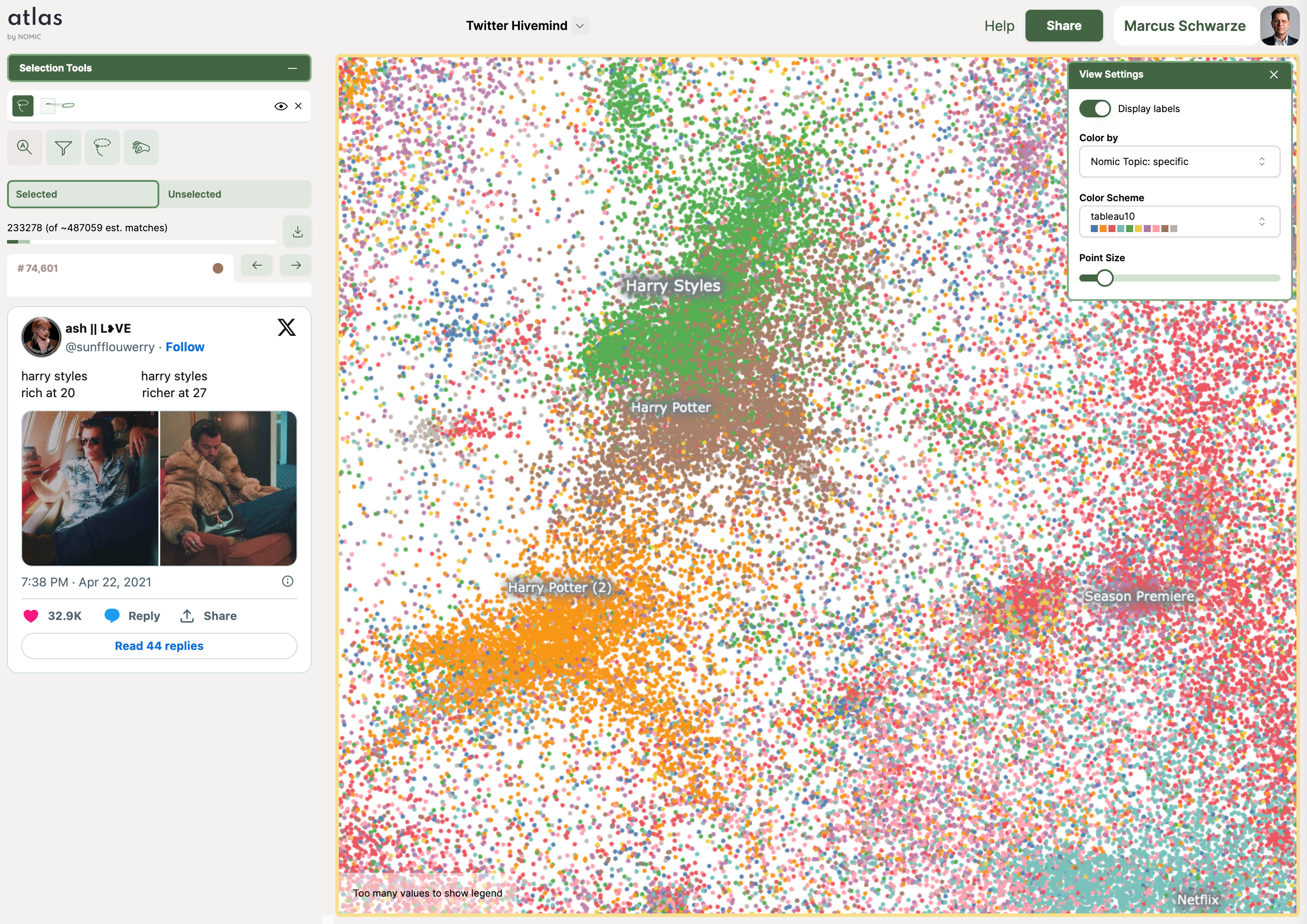
Nomic generiert daraus zunächst Punktwolken, beispielsweise aus Millionen von eingespeisten öffentlichen Tweets oder aus Wikipedia-Beiträgen. Und so schließt sich der Kreis: Die Daten können von Nomic, aber auch von anderen dazu verwendet werden, neue Sprachmodelle zu trainieren. Und es lassen sich sowohl öffentliche als auch private Datenpunkte festlegen – letztere für Informationen, die nicht für andere zugänglich sein sollen. Daraus wird letztlich Nomics Geschäftsmodell. Wer Geschäftsunterlagen vor der KI privat halten möchte, muss dafür bei Nomic zahlen.




Comments ()